こんにちはmasalifeです。
今回は関数を使って、特定の文字までを抽出する方法を紹介したいと思います。
使用する関数はInStr関数とLeft・Mid関数です。
InStr関数はあまりなじみがないかもしれませんが、
文字列式において、指定した文字までの位置を取得できる関数です。
このやり方を覚えておくと、ふとした時に役立つのでぜひ参考にしてみてください。
*やり方だけをすぐ知りたい方は【目次2:クエリでユーザー名とドメイン名に分割する】のみを読んでください。
目標と手順の確認
目標:メールアドレスをユーザー名とドメイン名に分割する
例としてメールアドレスをユーザー名とドメイン名に分割してみましょう。

メールアドレスは@より前がユーザー名、@から後がドメイン名という構成になっています。
手順
データを加工出来るか出来ないかは、規則性を言語化出来るかにかかっています。
今回は@というユーザー名とドメイン名を区別できる記号と規則性があるので加工が出来ます。
手順を整理すると次のようになります。
【ユーザー名の取得手順】
| 手順 | 使用する関数 | |
| ① | 左から数えて@より前の文字位置を取得 | InStr関数 |
| ② | ①で取得した文字位置まで、左から文字列を取得 | Left関数 |
【ドメイン名の取得手順】
| 手順 | 使用する関数 | |
| ① | 左から数えて@より後の文字位置を取得 | InStr関数 |
| ② | ①で取得した文字位置以降の文字列を取得 | Mid関数 |
クエリでユーザー名とドメイン名に分割する
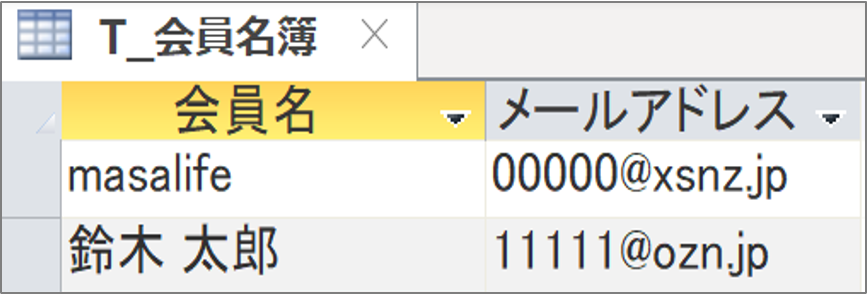
次のテーブル(T_会員名簿)のメールアドレスをクエリを使って、ユーザー名とドメイン名に分割しましょう。
クエリをデザインビューで開いて、
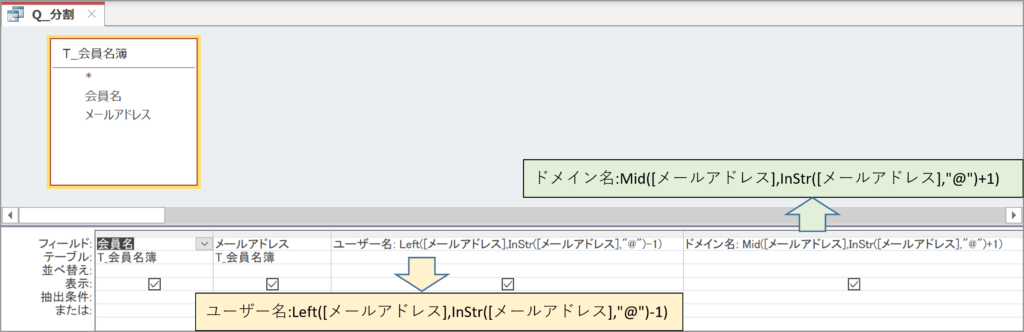
ユーザー名とドメイン名の列を挿入し、
| ユーザー名: Left([メールアドレス],InStr([メールアドレス],”@”)-1) |
| ドメイン名: Mid([メールアドレス],InStr([メールアドレス],”@”)+1) |
とそれぞれ入力します。
クエリを実行すると、

メールアドレスからユーザー名とドメイン名を分割して抽出出来ていることが確認できます。
抽出方法の仕組みを考える
文字位置を取得するInStr関数

まず、@より前の文字が左から数えていくつ目かを取得する必要があります。
文字列式において、指定した文字までの位置を取得するにはInStr関数を使用します。
InStr関数について、microsoft-officeサポートでは次のように示されています。
*今回必要な部分のみを簡略的に記載しています。
【構文】
InStr([start,] string1, string2 [,compare])
*microsoft-officeサポートより引用
| 引数 | 説明 |
| start | 検索の開始位置を指定。省略すると、左から検索をする。 |
| string1 | 検索の対象となる文字列式を指定。 |
| string2 | 検索の対象から検索する文字列式を指定。 |
| compare | 文字列を比較する種類を指定。省略可能。 |
引数のcompareの詳細については省略します。
知らなくても問題ありません。
それでは実際にクエリで戻り値を確認してみましょう。
次のようにクエリをデザインします。
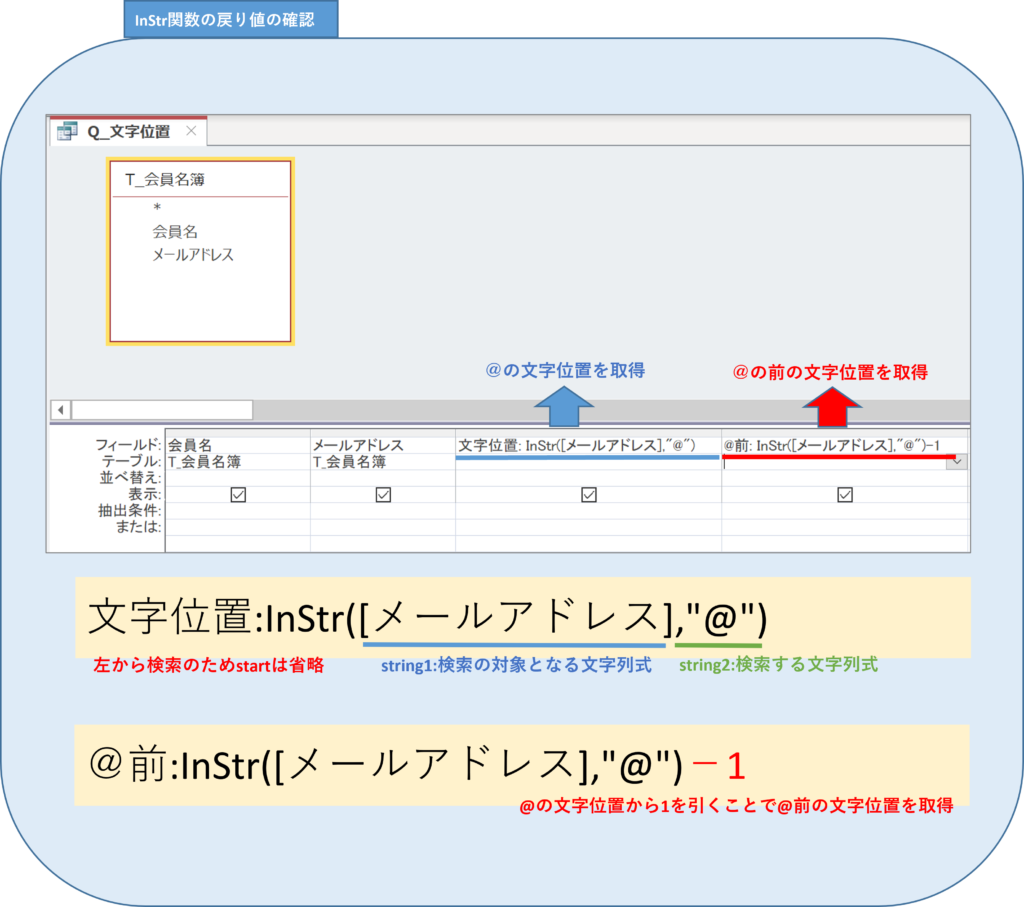
実行して結果を確認します。

@の文字位置は左から数えて6つ目であり、1つ前は5つ目であることが取得出来ましたので、
1つ前を取得する、InStr([メールアドレス],”@”)-1
をLeft関数の引数に指定することで、ユーザー名を取得出来ます。
同様の考え方で、@の1つ後はInStr([メールアドレス], “@”)+1で取得出来、Mid関数の引数に指定することで、ドメイン名を取得出来ます。
左から指定した数の文字列を取得するLeft関数(ユーザー名の取得)

文字列式において、左から指定した数の文字列を取得するにはLeft関数を使用します。
Left関数について、microsoft-officeサポートでは次のように示されています。
【構文】
Left(string,length)
*microsoft-officeサポートより引用
| 引数 | 説明 |
| string | 文字列式を指定 |
| length | 左から数えて取得する文字数を数値・数値式で指定 |
引数lengthに数値を指定すればいいのですが、ユーザー名である@より前の部分の数はメールアドレスによって変動します。
そのため、目次【文字位置を取得するInStr関数】で示した
InStr([メールアドレス],”@”)-1
を引数lengthに指定します。
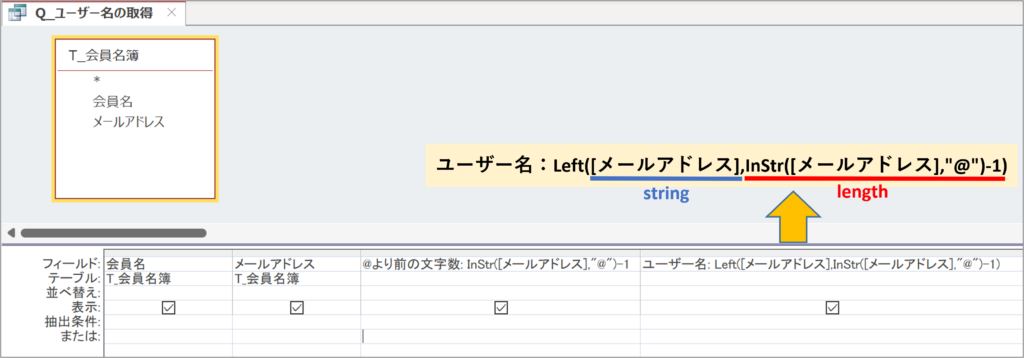
実行して結果を確認します。
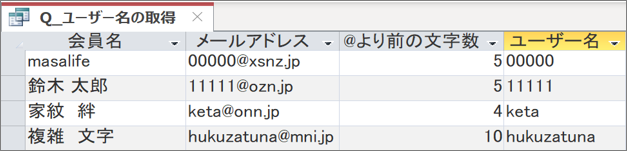
メールアドレスごとにユーザー名(@より前)が抽出されています。
指定した文字位置から、指定した文字の数を取得するMid関数(ドメイン名の取得)

文字列式において、指定した文字位置から、指定した文字の数を取得するにはMid関数を使用します。
Mid関数について、microsoft-officeサポートでは次のように示されています。
【構文】
Mid(string, start [, length ])
*microsoft-officeサポートより引用
| 引数 | 説明 |
| string | 文字列式を指定 |
| start | 文字の取得を開始する文字位置を指定 |
| length | startから取得する文字の数を指定。省略するとstartから、 すべての文字を取得する。 |
引数startに数値を指定し、lengthを省略すればいいのですが、ドメイン名である@より後の文字位置(start)はメールアドレスによって変動します。
そのため、目次【文字位置を取得するInStr関数】で示した
InStr([メールアドレス],”@”)+1
を引数startに指定します。
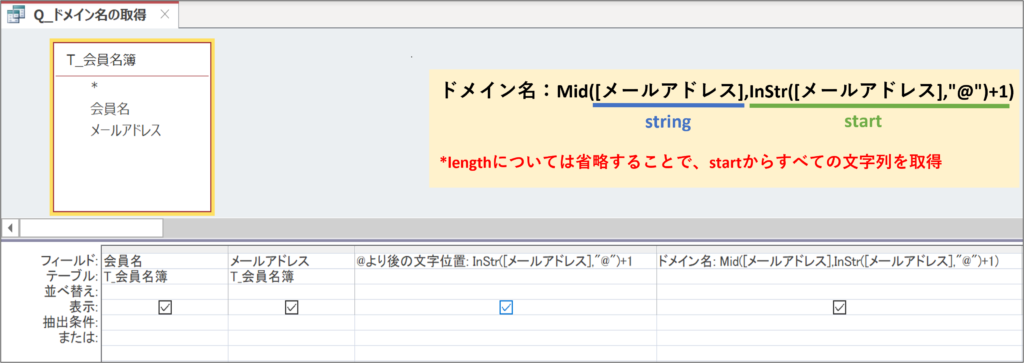
実行して結果を確認します。
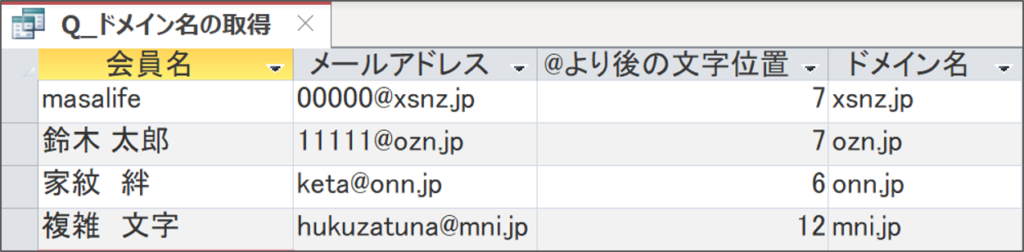
メールアドレスごとにドメイン名(@より後)が抽出されています。
さいごに
メールアドレスにはユーザー名とドメイン名の区別が@でされており、規則性がありました。
データを加工するには、まず規則性をしっかりと理解しなければなりません。
ファイル名と拡張子を「.(ドット)」で区別している等、
世の中には規則性があふれているので、そういう感覚で見てみるのも面白いかもしれません。
規則性に気付ける能力も養われると思います。
最後まで読んでいただきありがとうございました。